Learning Nonlinear Causal Reductions to Explain Reinforcement Learning Policies
Abstract
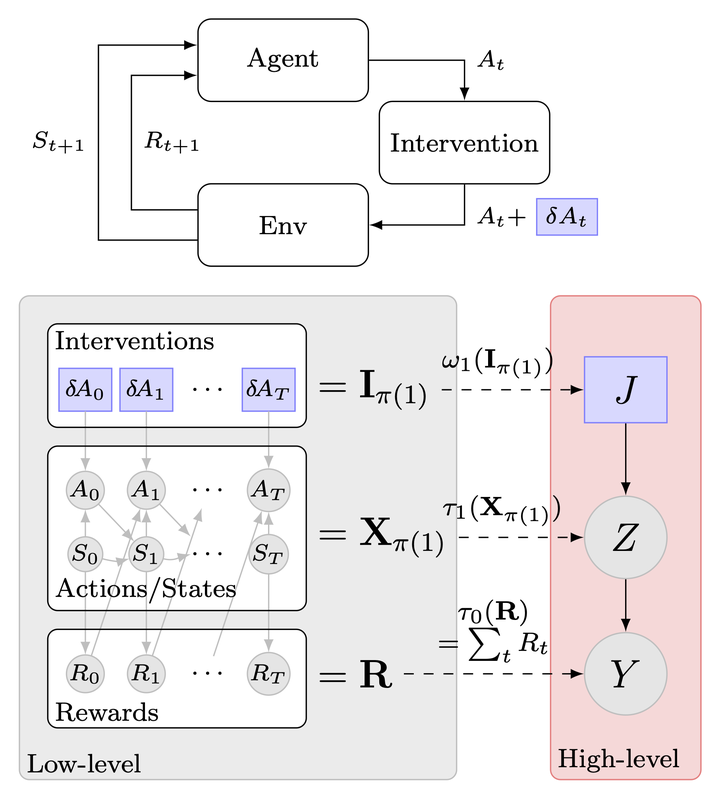
Why do reinforcement learning (RL) policies fail or succeed? This is a challenging question due to the complex, high-dimensional nature of agent-environment interactions. We take a causal perspective on explaining the global behavior of RL policies by viewing the states, actions, and rewards as variables in a low-level causal model. We introduce random perturbations to policy actions during execution and observe their effects on the cumulative reward, learning a simplified high-level causal model that explains these relationships. To this end, we develop a nonlinear Causal Model Reduction framework that ensures approximate interventional consistency, i.e., the simplified high-level model responds to interventions in a way consistent with the original complex system. We prove that for a class of nonlinear causal models, there exists a unique solution that achieves exact interventional consistency, ensuring learned explanations reflect meaningful causal patterns. Experiments on both synthetic causal models and practical RL tasks-including pendulum control and robot table tennis-demonstrate that our approach can uncover important behavioral patterns, biases, and failure modes in trained RL policies.
Armin Kekić
PhD Student in Causality and Machine Learning
My interests include high-dimensional time series forecasting, machine learning, network science and quantum dynamics.